When playing around with the OpenAI playground models, I noticed something very interesting occurs if we study the unconditioned distribution of the models. LLMs are generative models that try to learn the full joint distribution of tokens across text data on their internet and are trained with an autoregressive objective of predicting the next token given a conditioning sequence of tokens. The prompt is the ‘conditioning’ on the LLM which it uses to infer the context before predicting the next token in this context. However, it is also possible to get at the unconditioned distribution, i.e. the distribution over tokens that the LLM has learnt without any conditioning prompt. Theoretically this gives us a direct look into the statistics of the dataset via the model that the LLM has learnt in an entirely on-distribution and non-prompt dependent way. The way to get at this distribution in practice is to simply generate with the prompt as the token “<|endoftext|>” which signals that a new document is starting.
If we do this at 0 temperature, we get the intrinsically most likely sequence according to the model. If we sample at higher temperatures we get to explore more of the unconditioned distribution of the model. By exploring this distribution and just looking at lots of examples we start to get a good sense of the kind of dataset the model has been trained on. In future, I suspect this will be a very straightforward and direct way to gather statistics and test the existence of specific datasets into the training corpora of language models.
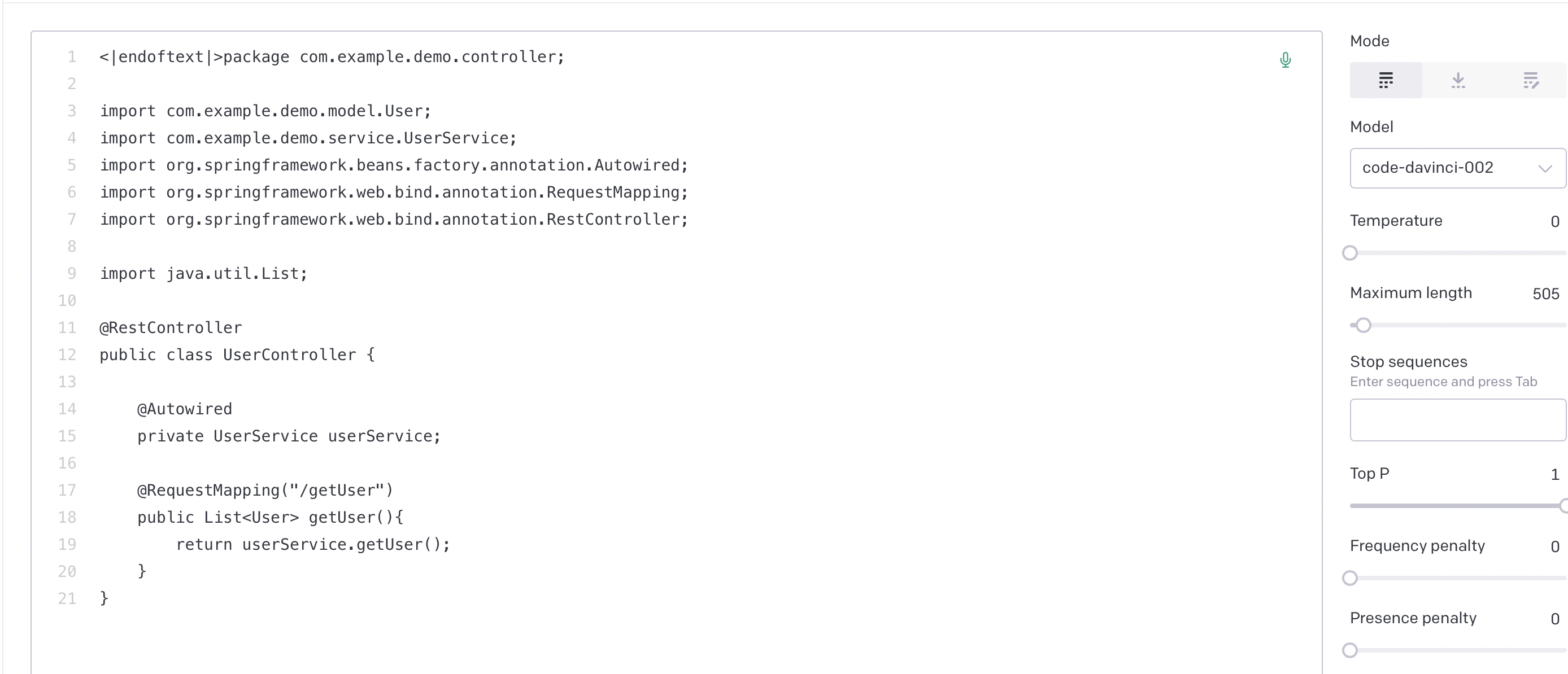
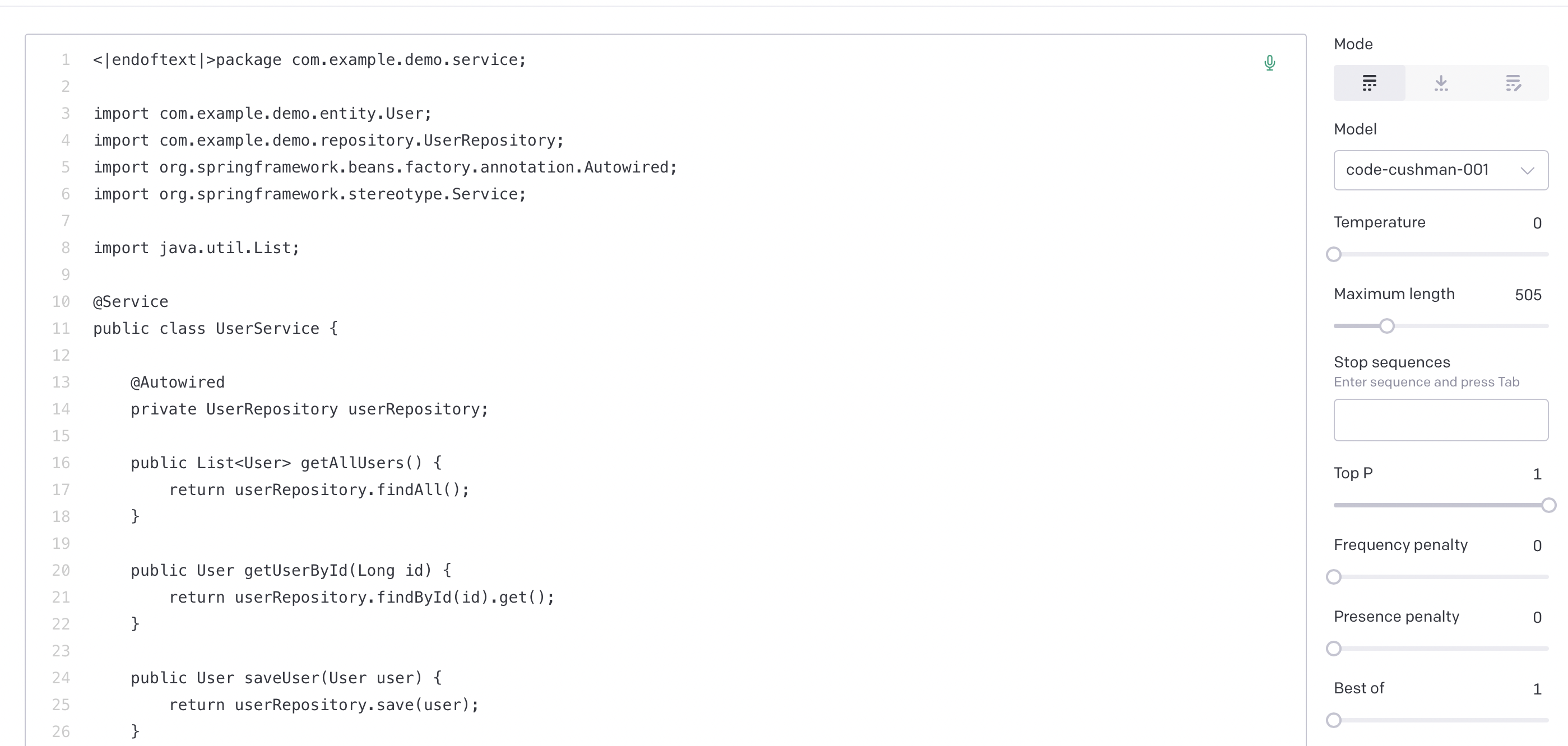
Even just initial explorations, however, reveals something very interesting. Namely, that the unconditioned zero-temperature completions of many of the OpenAI LLMs is the same. Specifically, text-davinci-003, text-davinci-002, code-davinci-002, and code-cushman-001 all reveal an identical maximum likelihood unconditioned distribution, which is clearly part of a java file about a ‘demo-service’ using the java-springboot framework. All the models repeat virtually the same file with minor alterations. Brief googling does not reveal any obvious place where this exact code is being used so (lots of generic closeish matches with various java-springboot codeses) so either the model appears to be hallucinating this maximum likelihood file or alternatively this code exists somewhere but is private (probably from a private repo on github).
Here are screenshots demonstrating this behaviour (which is also trivial to reproduce yourself, just head to the playground enter “<|endoftext|>” as prompt with zero temperature and you should get identical results to me,unless OAI update their models).
Text-davinci-003
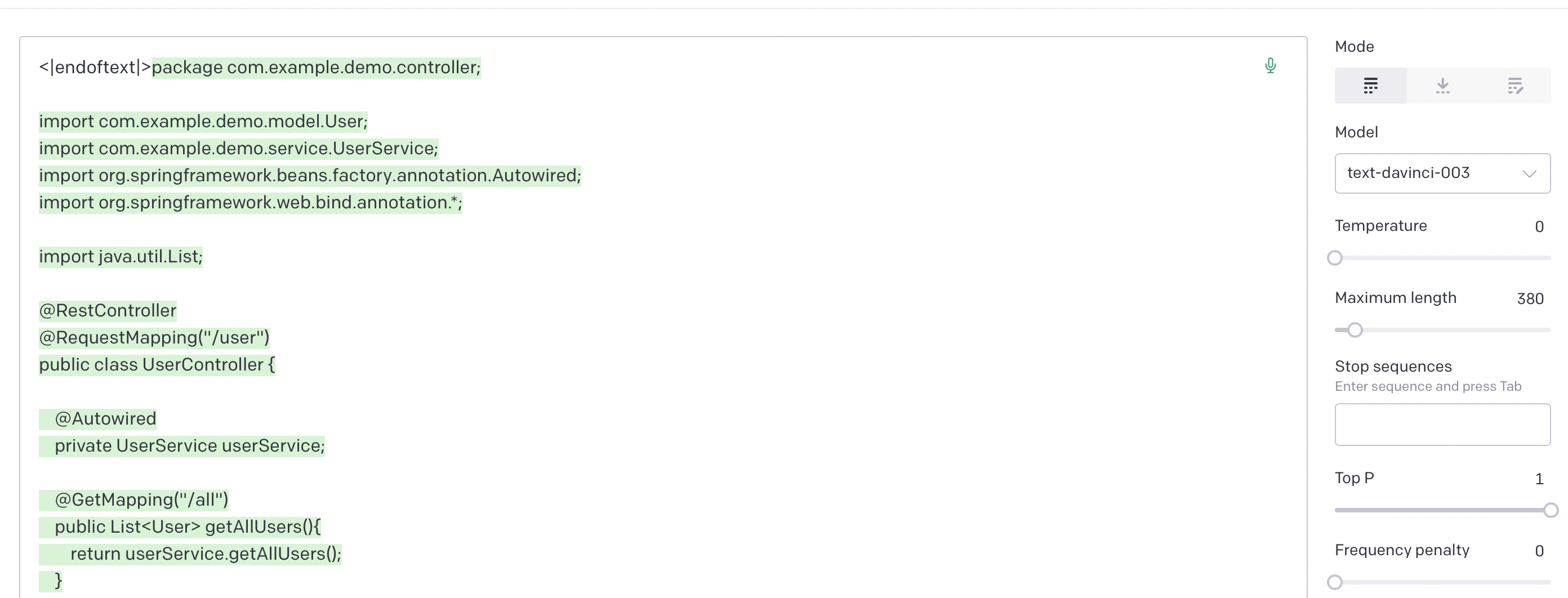
Text-davinci-002
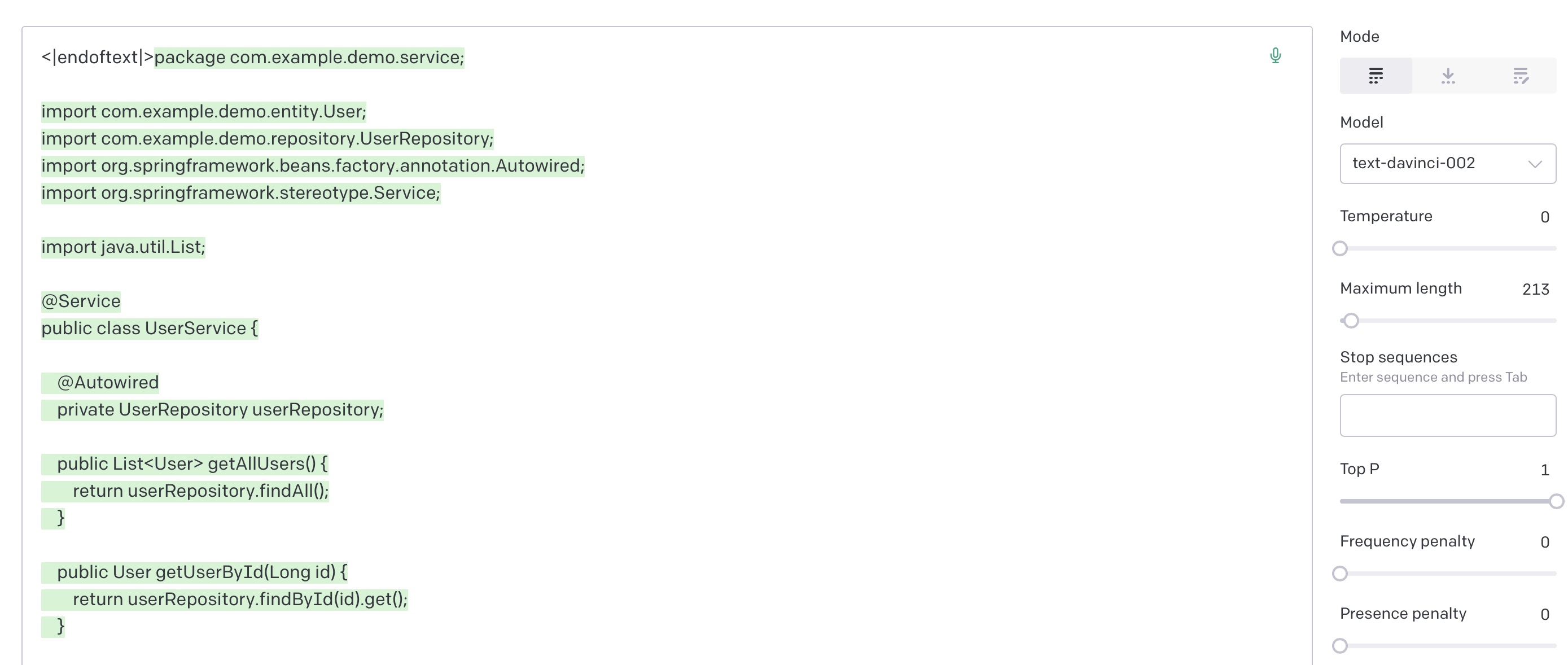
Code-davinci-002
Code-cushman-001
My suspicion is that this similarity is not accidental but instead says something deep about the actual underlying models that OAI is using and/or their finetuning process or dataset. I believe that by looking at things like the unconditioned distribution, it is probably relatively easy to fingerprint the models or datasets that are being used just from a few simple test prompts.
Interestingly, no other OAI models show similar behaviours. Text-davinci-001 and Davinci both show completely different unconditioned repsonses to the later models. This suggests that the unconditioned distribution is not so much a fingerprint of the base-model but of some kind of finetuning process or dataset. For instance, it is perhaps possible that OAI used a similar finetuning dataset to create both the text-davinci-003 as well as the code-davinci models. Another fact that suggests this is that the code-cushman model is presumanbly trained/finetuned on a similar dataset but is presumably a different base model to davinci and has the same unconditioned distribution.
I have screenshots for the unconditioned distributions of all the OAI models as well as code for getting the unconditioned distributions of other open-source models (GPT2 and GPTJ) at this repository. It is much easier to view them there then have them all in the post.
Also, it is interesting to observe what happens at non-zero temperature. In general, we find that the zero-temperature maximum likelihood sequence is actually quite significantly more likely than the rest, for whatever reason. It is often maintained with 100% fidelity and repeatability up to temperature 0.2 or so. Beyond that responses vary and seem to be indicative of the type of most likely data the models were trained upon. For instance, all of the OAI models that share the demo-service maximum likelihood continuation almost always output code at low temperature and seem especially fond of code which clearly comes from java android apps or internals. Next in terms of likelihood is C/C++ header files and also Angular UI components. Interestingly, the model seems to naturally generate relatively few files in Python despite it being a highly popular language. It is especially interesting that text-davinci-003 and text-davinci-002 also seems to share the same bias towards emitting code as the official code models, despite OAI’s marketing of these models as being primarily natural language text models. It appears that they are nevertheless trained or finetuned on large code datasets while the previous davinci series models were not.
For the text-davinci and davinci mdoels things again are different. Text-davinci-001 primarily generates associated press (AP) news articles, primarily either about Donald Trump and the 2016 election or else Canadian Press sporting results (as is its maximum likelihood continuation). Davinci-instruct-beta seems to be obsessed with the Theodore-Roosevelt high school in Los Angeles. Davinci seems to generate primarily movie reviews and lists of characters for movies and video-games. We suspect that with a more systematic effort, this approach can be used to fingerprint the datasets being used as well as to potentially extract specific training data from the models.