This is just a quick post to share a rough scheme I have for assessing the potential AI risk caused by specific models. It probably needs a lot more fleshing out and discussion to be fully general but I think it is a useful intuition pump.
When we think about what it means for an AI model to be dangerous, or capable of causing x-risk on short timelines, I think it is useful to separate out types of AI systems as well as the potential cause of the danger. The cause of the danger falls into basically two categories: misuse, and autonomous AI takeover. With misuse, we build powerful AI systems that let us build new technologies or manipulate the world in increasingly powerful ways and some bad actor misuses them either intentionally or unintentionally causing mass damage or an extinction event. This can happen even when the AI itself is well ‘aligned’ with the human’s intent. An example potential scenario here would be an AI that is trained really well to understand virology and molecular biology is asked to design a super-virus that wipes out humanity, and does so.
The second case is autonomous AI takeover. The classic case here is that we create a mis-aligned agent in the world that is free to e.g. plot to take over key systems and use these to destroy humanity in order to do whatever goals it has, such as creating paperclips. Danger here requires misalignment while danger from misuse persists even in the face of solving the technical problem of alignment.
My general judgment here is that misuse is a big and slightly underappreciated problem by people focused on technical AI safety, but that, broadly, it can be handled by existing legal and societal mechanisms for regulating the use of new technologies. It is primarily a problem of governance and law and mechanism design rather than one of computer science and machine learning.
If we turn to the problem of autonomous AI takeover, we can think of the AI requiring two components of capability to pose a serious threat. General Knowledge, and Agency. By both of these I mean very specific things:
By General Knowledge, I specifically mean that the AGI is trained on a very broad domain which is very similar, and likely includes, a significant amount of knowledge of our world. This is to contrast with ‘narrow’ AI systems which are only trained in some small domain such as a board-game like Chess, or on some narrow task like folding proteins and nothing else. LLMs are an example of systems which have been exposed to general knowledge since their pretraining corpus of much of the internet essentially contains the sum of all human knowledge.
By Agency, I mean the system can be thought of as directly optimizing for some state of the world (and not simply performing amortized approximate Bayesian inference of some posterior distribution of the data). The system specifically tries to steer its world-state into some low entropy configuration across long time horizons. A classic example of an Agentic (but narrow) AI is something like Alpha-go which is superhuman at steering go states into low entropy distributions (where it has won).
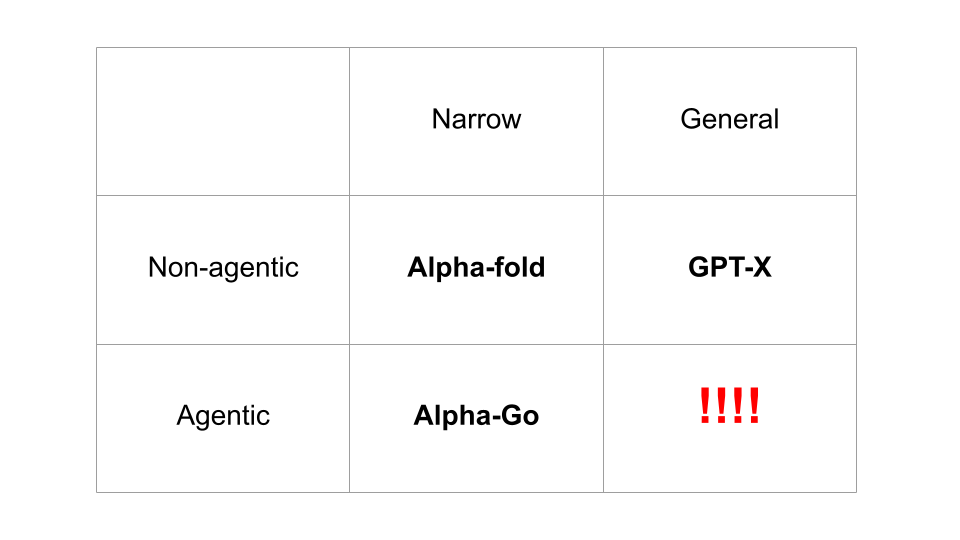
There is potentially a third necessary component – direct affordances to act on the world. It is much easier for an AI to take over the world if it has direct ways of interacting with the world – i.e. it is connected to the internet, it can write text on a screen, this kind of thing. An AI, even if fully general and fully agentic would have a hard time ‘escaping’ if the only thing it could do was output tic-tac-toe moves. However technically, it might not be impossible. We can assume this as a third condition.
My general feeling is that to cause X-risk, it requires both general knowledge and agency. A very general and intelligent system will not cause autonomous danger if it is not agentic. There are some potential ways for Oracle AIs as they have been conceptualized to pose risks, but none of them seem super convincing or likely in practice. There is definitely a very high potential for risks from misuse, however, as these systems become more powerful. On the other hand, a very powerful agent is not necessarily dangerous if it is narrow. We have had extremely superhuman agents in narrow domains such as board games for a long time, and they are obviously no danger.
Perhaps the biggest update 1 is that these dimensions seem pretty orthogonal in practice. Large language models have shown that it is possible to construct extremely general and ‘intelligent’ agents which lack any sense of agency or goals. Arguably GPT-4 is already AGI in the sense of a general intelligence which knows more than most humans about most topics and is already a highly fluent reasoner. However, it does not appear dangerous because it mostly lacks agency, goals, and direct ways to interact with the world. Similarly, alpha-go is extremely superhuman at Go but is not dangerous because it cannot ‘escape the box’ of Go to have any impact in the real world.
The main focus of alignment therefore, has to be understanding and constraining the creation and behaviours of the fourth quadrant– general and agentic systems – since this is where the danger lies. This will likely require some combination of governance and technical solutions.
This may seem super obvious but it has some moderately non-obvious implications. Firstly, non-agentic models trained with unsupervised losses to amortizedly optimize some objective, such as GPT-N, seem surprisingly non-dangerous. This, I think, is an update the alignment community is slowly making. Secondly, creating even extremely powerful agents is also safe, so long as they are very narrow in scope and domain. This potentially lets us test out alignment methods on very superhumanly powerful agents safely, by essentially creating narrow test domains for agents and determining the degree to which we can align these agents to our desired objectives and values.
-
Which, in retrospect should not have been surprising and is testament to how bad the AI safety community’s general models were. ↩