Recently, LLM-based agents have been all the rage – with projects like AutoGPT showing how easy it is to wrap an LLM in a simple agentic loop and prompt it to achieve real-world tasks. More generally, we can think about the class of ‘scaffolded’ 1 LLM systems – which wrap a programmatic scaffold around an LLM core and chain together a number of individual LLM calls to achieve some larger and more complex task than can be accomplished in a single prompt. The idea of scaffolded LLMs is not new, however with GPT4, we have potentially reached a threshold of reliability and instruction following capacity from the base LLM that agents and similar approaches have become viable at scale. What is missing, and urgent, however, is an understanding of the larger picture. Scaffolded LLMs are not just cool toys but actually the substrate of a new type of general-purpose natural language computer.
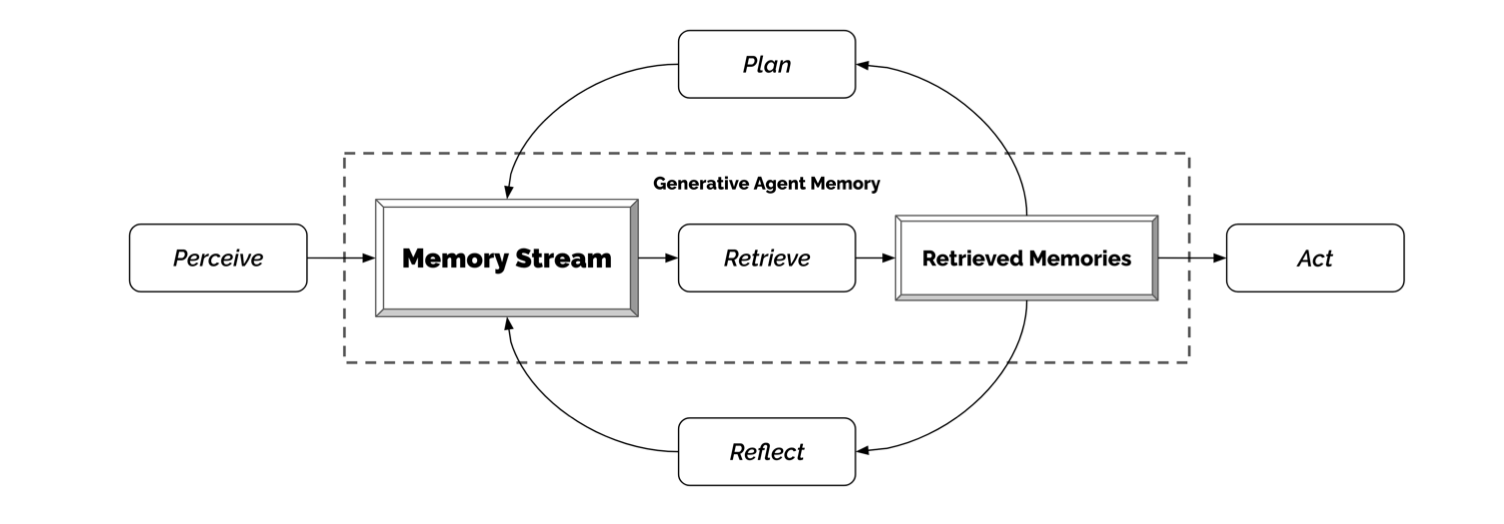
Take a look at, for instance, the ‘generative agent’ architecture from a recent paper. The core of the architecture is an LLM that receives instructions and executes natural language tasks. There is a set of prompt templates that specify these tasks and the data for the LLM to operate on. There is a memory that stores a much larger context than can be fed to the LLM, and which can be read to and written from by the compute unit. In short, what has been built looks awfully like this:
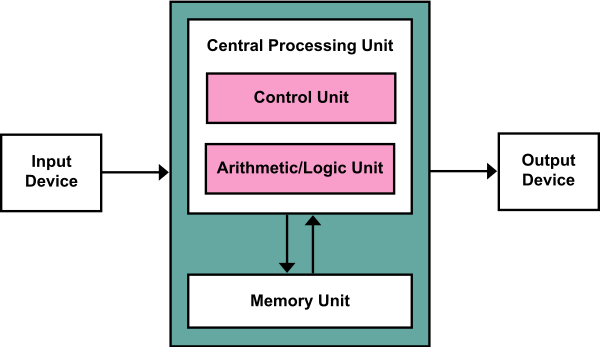
What we have essentially done here is reinvented the von-Neumann architecture and, what is more, we have reinvented the general purpose computer. This convergent evolution is not surprising – the von-Neumann architecture is a very natural abstraction for designing computers. However, if what we have built is a computer, it is a very special sort of computer. Like a digital computer, it is fully general, but what it operates on is not bits, but text. We have a natural language computer which operates on units of natural language text to produce other, more processed, natural language texts. Like a digital computer, our natural language (NL) computer is theoretically fully general – the operations of a Turing machine can be written as natural language – and extremely useful: many systems in the real world, including humans, prefer to operate in natural language. Many tasks cannot be specified easily and precisely in computer code but can be described in a sentence or two of natural language.
Armed with this analogy, let’s push it as far as we can go and see where the implications take us.
First, let’s clarify the mappings between scaffolded LLM components and the hardware architecture of a digital computer. The LLM itself is clearly equivalent to the CPU. It is where the fundamental ‘computation’ in the system occurs. However, unlike the CPU, the units upon which it operates are tokens in the context window, not bits in registers. If the natural type signature of a CPU is bits -> bits, the natural type of the natural language processing unit (NLPU) is strings -> strings. The prompt and ‘context’ is directly equivalent to the RAM. This is the easily accessible memory that can be rapidly operated on by the CPU. Thirdly, there is the memory. In digital computers, there are explicit memory banks or ‘disk’ which have slow access memory. This is directly equivalent to the vector database memory of scaffolded LLMs. The heuristics we currently use (such as vector search over embeddings) for when to retrieve specific memory is equivalent to the memory controller firmware in digital computers which handles accesses for specific memory from the CPU. Finally, it is also necessary for the CPU to interact with the external world. In digital computers, this occurs through ‘drivers’ or special hardware and software modules that allow the CPU to control external hardware such as monitors, printers, mice etc. For scaffolded LLMs, we have plugins and equivalent mechanisms. Finally, there is also the ‘scaffolding’ code which surrounds the LLM core. This code implements protocols for chaining together individual LLM calls to implement, say, a ReAct agent loop, or a recursive book summarizer. Such protocols are the ‘programs’ that run on our natural language computer.
Given these equivalences, we can also think about the core units of performance. For a digital computer, these are the amount of operations the CPU can perform (FLOPs) and the amount of RAM memory the system has available. Both of these units have exact equivalents for our natural language computer. The RAM is just the context length. GPT4 currently has an 8K context or an 8kbit RAM (theoretically expanding to 32kbit soon). This gets us to the Commodore 64 in digital computer terms, and places us in the early 80s. Similarly, we can derive an equivalent of a FLOP count. Each LLM call/generation can be thought of as trying to perform a single computational task – one Natural Language OPeration (NLOP). For the sake of argument, let’s say that generating approximately 100 tokens from a prompt counts as a single NLOP. From this, we can compute the NLOPs per second of different LLMs. For GPT4, we get on the order of 1 NLOP/sec. For GPT3.5 turbo, it is about 10x faster so 10 NLOPs/sec. Here there is a huge gap from CPUs which can straightforwardly achieve billions of FLOPs/sec. However, a single NLOP is much more complex than a CPU processor instruction, so a direct comparison is unfair. However, the NLOP count is still a crucial metric. As anybody who has done any serious playing with GPT4 will know, the sheer slowness of GPT4s responses are the key bottleneck, rather than the cost.
Given that we have units of performance, the next question is whether we should expect Moore’s law-like, or other exponential improvements in their capabilities. Clearly, since the whole LLM paradigm is only 3 years old, it is too early to say anything definitive. However, we have already observed many doublings. Context length has 4x’d (2k to 8k) since GPT3 in just 3 years. The power of the underlying LLM and speed of NLOPs has also increased massively (probably at least 2x from GPT3 -> GPT4) although we lack exact quantitative measurements. All of this has been driven by the underlying exponentially increasing scale and cost of LLMs and their training runs, with GPT4 costing an estimated 100m, and with the largest training runs expected to reach 1B within the next two years. My prediction here is that exponential improvements continue at least for the new few years and likely beyond. However, it seems likely that within 5-10 years we will have reached the cap of the amount of money that can be feasibly spent on individual training runs (10B seems the rough order of magnitude that is beyond almost any player). After this, what matters is not scaling resource input, but the efficnent utilization of parameters and data, as well as the underlying improvements in GPU hardware.
Beyond just defining units of performance, what potential predictions or insights does conceptualizing scaffolded LLMs as natural language computers bring?
Programming languages
The obvious thing to think about when programming a digital computer is the programming language. Can there be programming languages for NL computers? What would they look like? Clearly there can be. We are already beginning to build up the first primitives. Chain of thought. Selection-inference. Self-correction loops. Reflection. These sit at a higher level of abstraction than a single NLOP. We have reached the assembly languages. CoT, SI, reflection, are the mov, leq and goto, which we know and love from assembly. Perhaps with libraries like langchains and complex prompt templates, we are beginning to build our first compilers, although they are currently extremely primitive. We haven’t yet reached C. We don’t even have a good sense of what it will look like. Beyond this simple level, there are so many more abstractions to explore that we haven’t yet even begun to fathom. Unlocking these abstractions will require time as well as much greater NL computing power than is currently available. This is because building non-leaky abstractions comes at a fundamental cost. Functional or dynamic programming languages are always slower than bare-metal C and this is for a good reason. Abstractions have overheads, and while you are as limited by NLOPs as we currently are, we cannot usefully use or experiment with these abstractions; but we will.
Beyond just programming languages, the entire space of good ‘software’ for these natural language computers is, at present, almost entirely unexplored. We are still trying to figure out the right hardware and the most basic assembly languages. We have begun developing simple algorithms – such as recursive text summarization – and simple data structures such as the ‘memory stream’, but these are only the merest beginnings. There are entire worlds of natural language algorithms and datastructures that are completely unknown to us at present lurking at the edge of possibility.
Theory
For digital computers, we had a significant amount of theory in existence before computers became practicable and widely used. Turing and Godel and others did foundational work on algorithms before computers even existed. Lambda calculus also was started in the 30s and became a highly developed subfield of logic by the 50s while computers were expensive and rare. For hardware design, boolean logic had been known for a hundred years before it became central to digital circuitry. Highly sophisticated theories of algorithmic complexity, as well as type theory and programming language design ran alongside Moore’s law for many decades. By contrast, there appears to be almost no equivalent formal theory of NL computers. Only the most basic steps forward such as the simulators frame were published last year.
For instance, the concept of an NLOP is almost completely underspecified. We do not have any ideas of the bounds of a single NLOP (apart from ‘any natural language transformation’). We do not have the equivalent of a minimal natural language circuit capable of expressing any NL program, such as a NAND gate in digital logic. We have no real concept of how a programming language comprised of NLOPs would work or the algorithms which they would be capable of. We have no equivalent of a truth table for the specification of correct behaviour of low level circuitry.
Execution model
It is also natural to think about the ‘execution model’ of a natural language program. A CPU classically has a linear execution model where instructions are read in one by one and then executed in series. However, you can call a LLM as many times as you like in parallel. The natural execution model of our NL computer is instead an expanding DAG of parallel NLOPs, constrained by the inherent seriality of the program they are running, but not by the ‘hardware’. In effect, we have reinvented the dataflow architecture.
Computer hardware is also naturally homoiconic – CPU opcodes are just bits, like everything else, and can be operated on the same as ‘data’. There is no principled distinction between ‘instruction’ and ‘data’ other than convention. The same is true of natural language computers. For a single NLOP, the prompt is all there is – with no distinction between ‘context’ and ‘instruction’. However, like in a digital computer, we are also starting to develop conventions to separate commands from semantic content within the prompt. For instance, the recent inclusion of a ‘system prompt’ with GPT4 hints that we are starting to develop protected memory regions of RAM. In common usage, people often separate the ‘context’ from the ‘prompt’, where the prompt serves even more explicitly as an op-code. For instance the ‘prompt’ might be: ‘please summarize these documents’: … [list of documents]. Here, the summary command serves as the opcode and the list of documents as the context in the rest of RAM. Such a call to the LLM would be a single NLOP.
Memory hierarchy
Current digital computers have a complex memory hierarchy, with different levels of memory trading off size and cheapness vs latency. This goes from disk (extremely large and cheap but slow) to RAM (moderate in all dimensions) to on-chip cache which is extremely fast but very expensive and constrained. Our current scaffolded LLMs only have two levels of hierarchy ‘cache/RAM’ – which is the prompt context fed directly into the LLM, and ‘memory’ which is say a vector database or set of external facts. It is likely that as designs mature, we will develop additional level of the memory hierarchy. This may include additional levels of cache ‘within’ the architecture of the LLM itself – for instance dense context vs sparse / locally attended context, or externally by parcelling a single NLOP into a set of LLM subcalls which use and select different contexts from longer term memory. One initial approach to this is using LLMs to rank the relevance of various pieces of context in the long-term memory and only feeding the most relevant into the context for the actual NLOP LLM call. Here latency vs size is traded of in the cost and time needed to perform this LLM ranking step.
Foundation models as cognitive hardware
While, obviously, every part of the stack of a scaffolded LLM is technically software, the analogy between the core LLM and the CPU hardware is stronger than an analogy. The base foundation models, in many ways, have more properties of classical hardware than software – we can think of them as ‘cognitive hardware’ underlying the ‘software’ scaffolding. Foundation models are essentially gigantic I/O black boxes that sit in the middle of a surrounding scaffold. However, absent any powerful interpretability or control tools, it is not easy to take them apart, or debug them, or even fix bugs that exist. There is no versioning and essentially no tests for their behaviour. All we have is an inscrutable, and incredibly expensive, black-box. From a ML-model producer, they also have similar characteristics. Foundation models are delicate and expensive to design and produce with slow iteration cycles 2. If you mess up a training run, there isn’t a simple push-to-github fix; it is potentially a multi-month wait time to restart training. Moreover, once a model ships, many of its behaviours are largely fixed. You definitely have some control with finetuning and RLHF and other post-training approaches, but much of the behaviour and performance is baked in at the pretraining stage. All of this is similar to the problems hardware companies face with deployment.
Moreover, like hardware, foundation models are also highly general. A single model can achieve many different tasks and, like a CPU, run a wide array of different NLOPs and programs. Additionally, foundation models and the ‘programs’ which run on them are already somewhat portable, and likely to become more so. Theoretically, switching to a new model is as simple as changing the API call. In practice, it rarely works out that way. A lot of prompts and failsafes and implicit knowledge specific to a certain LLM usually ends up hardcoded into the ‘program’ running on the LLM in practice, to handle its unreliability and many failure cases. All of this limits immediate portability. But this is simply a symptom of having insufficiently developed abstractions and programming too close to the metal (too close to the neurons?). Early computer programs were also written with a specific hardware architecture in mind and were not portable between them – a situation which lasted widely well into the 90s. As LLMs improve and become more reliable, and people develop better abstractions for the programs that run on them, portability will likely also improve and the hardware-software decoupling and modularization will become more and more obvious, and more and more useful.
To a much lesser extent, this is also true of the other ‘hardware’ parts of the scaffolded LLM. For instance, the memory is usually some vector database like faiss which to most people is equally a black-box API call which is hard to replace and adapt. This contrasts strongly with the memory-controller ‘firmware’ (which is the coded heuristics of how to address and manage the LLMs long-term memory) and is straightforward to understand, update, and replace. What this means is that once natural language programs and ‘software’ starts spreading and becoming ubiquitous, we should expect approximately the same dynamics as hold between hardware and software today. Producing NL programs will be much cheaper and with lower costs to entry than producing the ‘hardware’ which will be prohibitively expensive for almost everybody. The NL software should have much faster iteration time than the hardware and become the primary locus of distributed innovation.
Fundamental differences from digital computers
While we have run a long way with the analogy between scaffolded LLMs and digital computers, the analogy also diverges in a number of important ways, almost all of which center around the concept of a NLOP and the use of a LLM as the NLPU. Unlike digital CPUs, LLMs have a number of unfortunate properties that make creating highly reliable chained programs with them difficult at present. The expense and slowness of NLOPs is already apparent and currently highly constrain program design. Likely these issues will be ameliorated with time. Additional key differences are the unreliability, underspecifiability, and non-determinism of current NLOPs.
Take perhaps a canonical example of a NLOP: text summarization. Text summarization seems like a useful natural language primitive. It has an intrinsic use for humans, and it is beginning to serve a vital role in natural language data structures in summarizing memories and contexts to fit within limited context. Unlike a CPU op, summarization is underspecified. The mapping from input to output is one to many. There are many potential valid summaries of a given text, of varying qualities. We don’t have a map to the ‘optimal’ summary, and it is even unclear what that would mean given the many different constraints and objectives of summarizing. Summarization is also unreliable. Different LLMs 3 and different prompts (and even the same prompt at high temperature) can give the same summary at widely varying levels of quality and utility. LLMs are not even deterministic, even at zero temperature (while surprising, this is a fact as you can easily test yourself. This is due to nondeterministic CUDA optimizations being used to improve inferencing speed). All of this is highly unlike digital hardware which is incredibly reliable and has a fixed and known I/O specification.
This likely means that before we can even start building powerful abstractions and abstract languages, the reliability of individual NLOPs must be significantly improved. Abstractions need a reliable base. Digital computers are fantastic for building towers of abstraction upon precisely because of this reliability. If you can trust all of the components of the system to a high degree, then you can create elaborate chains of composition. Without this, you are always fighting against chaotic divergence. Reliability can be improved both by better prompting, better LLM components, better tuning, and by adding heavy layers of error correction. Error correction itself is not new to hardware – huge amounts of research has been expended in creating error correcting codes to repair bit-flips. We will likely need similar ‘semantic’ error correcting codes for LLM outputs to be able to stitch together extended sequences of NLOPs in a highly coherent and consistent way.
However, although the unreliability and underspecifiedness of NLOPs is challenging to build upon, it also brings great opportunities. The flexibility of LLMs is unmatched. Unlike a CPU which has a fixed instruction-set or set of registered and known op-codes, a LLM can theoretically be prompted to attempt almost any arbitrary natural language task. The set of op-codes is not fixed but ever growing. It is as if we are constantly discovering new logic gates. It remains unclear how large the set of task primitives is, and whether indeed there will ever be a full decomposition in the way there is for logical circuits. Beyond this, it is straightforward to merge and chain together prompts (or op-codes) with a semi-compositional (if unreliable) effect on behaviour. We can create entire languages based on prompt templating schemes. From an instruction set perspective, while for CPUs, RISC seems to have won out, LLM based ‘computers’ seem to intrinsically be operating in a CISC regime. Likely, there will be a future (or current) debate isomorphic to RISC vs CISC about whether it is better to chain together lots of simple prompts in a complex way, or use a smaller number of complex prompts.
-
The reason I am saying ‘scaffolded’ LLMs instead of ‘agentized’ LLMs as in a recent post is that, while agents are hot right now, the idea is broader. Not all natural language programs need to be agents. Agents are a natural abstraction suited to a particular type of task. But there are others. ↩
-
An interesting aspect of this analogy is that it clarifies the role and economic status of current foundation model providers like OpenAI. These essentially occupy an identical economic niche to the big chip-makers of the digital computer era such as Intel. The structure of their business is very similar. Training foundation models incurs massive fixed capital costs (as does building new chip fabs). They face constantly improving technology and new generations of tech which is vastly more powerful (Moore’s law vs contemporary rapid AI scaling). They sell a commodity product (chips vs API calls) at large volume with a high margin but also substantial marginal costs (actually manufacturing each chip vs inferencing a model). If these equivalences hold then we can get some idea about what the likely long run shape of this industry will look like – namely, the current and historical semiconductor industry. We should expect consolidation into a few main oligopolic players, where each have massive fixed costs and remain in fairly fierce competition, but that they never print money with extremely high margins in the same way that SAAS or software based companies tend to. ↩
-
NLOPs also differ crucially from more standard FLOPs in that they have different levels of ‘intrinsic difficulty’. A small language model might be capable of some tasks, but others might require a large state of the art one. As NL programs become more sophisticated and elaborate, it is likely that there will be an increasing understanding of the difficulty of specific ops and a delegation of each op to the smallest and cheapest language model with the capability to reliably perform this op. Thus, NL programs will not have a uniform ‘CPU’ (LLM) core but will be comprised of a number of heterogenous calls to many different language models of different scales and specializations. ↩