Epistemic Status: Much of this draws from my studies in neuroscience and ML. Many of the ideas in this post are heavily inspired by the work of Steven Byrnes and the authors of Shard Theory. However, it speculates quite a long way in advance of the scientific frontier and is almost certainly incorrect in many aspects. However, I believe the core point is true and important.
TLDR for those who don’t want to read the full post. Some of this may not make a huge amount of sense without context. Human values are primarily linguistic concepts encoded via webs of association and valence in the cortex learnt through unsupervised (primarily linguistic) learning. These value concepts are bound to behaviour through a.) a combination of low-level RL and associations with low-level reward signals and integrated into the amortized policy, and b.) linguistic based associations and behavioural cloning of socially endorsed or others’ behaviours. This is mediated by our ‘system 2’ at primarily a linguistic level consisting of iterative self-conditioning through the world model. The important representation space for human values is the latent space of the linguistic world model and the web of associations therein as well as connections between it and low-level policies and reward models from the RL subsystems. The geometry of the embeddings in the latent space is primarily influenced by the training data – i.e. culture and behavioural history, although the association of different latent concepts with positive and negative valence can be driven by the RL system which interfaces with primary rewards. The geometry of the latent space can also be rewritten with continual learning on self-prompts or external stimuli.
In AI alignment, the goal is often understood to be aligning an AGI to human values. Then, typically, the flow of logic shifts to understanding alignment: how to align an AGI to any goal at all. The second element of the sentence – human values – is much less discussed and explored. This is probably partially because alignment sounds like a serious and respectable computer science problem while exploring human values sounds like a wishy-washy philosophy/humanities problem which we assume is either trivially solvable, or else outside the scope of technical problem solving. A related view, which draws implicitly from the orthogonality thesis, but is not implied by it, is that the alignment problem and the human values problem are totally separable: we can first figure out alignment to anything and then after that figure out human values as the alignment target. Since, if this is correct, there is no point understanding human values until we can align an AGI to anything, the correct order is to first figure out alignment, and only after that try to understand human values.
I think this view is wrong and that the alignment mechanism and the alignment target do not always cleanly decouple. This means we can leverage information about the alignment target to develop better or easier alignment methods 1. If this is the case, we might benefit from better understanding what human values actually are, so we can use information about them to design alignment strategies. However, naively, this is hard. Human values appears to be an almost intentionally nebulous and unspecific term. What are human values? What is their type signature (is this even a meaningful question?). How do they come about?
Here, we try to attack this problem through the lens of neuroscience and machine learning. Specifically, we want to understand the computational anatomy of human values. Namely, what kind of things they are computationally? How do they form? How does the functional architecture of the brain enable such constructs to exist, and how does it utilize them to guide action? If we can understand human values at this computational and mechanistic level, then we might gain insight into how to implement these values in ML systems.
Firstly, it is important to recognize that despite lots of confused existing philosophy, this is not an impossible task. Human values exist. They exist and guide the actions of real humans in the real world. They serve as an existence proof that some level of alignment to some code of ‘moral’ behaviour is possible for intelligent general agents.
This post is my first attempt at an answer to the question of the computational anatomy of human values. Here I put forward a speculative neuroscientific proposal and hypothesis for how human values form and the kind of thing that they are, as well as the high level interactions between computational components in the brain that serve to create values. Much of this is highly speculative. So little is known about the neuroscience of human values that the actual neurophysiology is highly contentious, although the high level details and functional view of the brain systems proposed here is, I think, broadly correct. Philosophically, this post is also heavily reductionist in that it considers values from a neutral position as the outputs of a computational process and subscribes to no moral realist theories about what the ‘true’ human values are.
To begin to understand how human values actually work, it is important first to understand what they are not. Specifically, what they are not is utility functions and humans are not utility function maximizers. This is quite obvious if we observe how humans act in reality, which differs strongly from a utility maximizing model. Specifically,
1.) Humans don’t seem to very strongly optimize for anything, except perhaps the fulfillment of basic drives (food, water etc)
2.) Humans often do not know what exactly they want out of life. This kind of existential uncertainty is not something a utility maximizer ever faces
3.) Human values are often contradictory and situationally dependent in practice.
4.) Humans often act against their professed values in a wide variety of circumstances.
5.) Humans often change their values (and sometimes dramatically) due to receiving new data either in the form of conversations and dialogue with people, social pressure, assimilating into a culture, or just reading and absorbing new world views.
6.) Most widely held philosophies of values and ethics and do not cash out into consequences at all. Consequentialism and utilitarianism are highly artificial doctrines that took thousands of years for humans to invent, are challenging for almost everyone to viscerally feel, and are almost never implemented in practice by real humans 2.
All of these properties differ very strongly from the default utility maximization picture of AGI. Any theory of human values that hopes to be accurate has to explain all of these phenomena parsimoniously (as well as many more). The theory that human values can be well represented as a utility function and humans as utility maximizers for this utility function satisfies none of them. This is not just due to people being ‘irrational’. It is a more fundamental fact of our cognitive architecture. Humans do not have the wiring to be true utility maximizers. But what are we instead? How does our own cognitive architecture lead to human values? And how can we design AI systems in the same way?
To solve this, we first need to understand what the computational architecture underpinning human cognition is. Luckily, ML and neuroscience have just about converged on a high level picture for how human decision-making and value learning actually occurs. To briefly jump to the end, my hypothesis is that human values are primarily socially constructed and computationally exist primarily in webs of linguistic associations (embeddings) in the cortex (world model) in an approximately linear vector space. Effectively, values exist as linguistic pointers and, to some extent, natural abstractions within linguistic space. These values are only loosely coupled to deeper innate human drives and can be updated and drive behaviour independently of them (although the innate drives and dispositions affect the representations in the world model to some extent). Moreover, these values primarily drive action through iterative planning based on conditioning the world model based on these linguistic signifiers which is learnt through frontal cortex meta-RL.
General neuroscience of human intelligence
Now let’s return to the foundational neuroscience. At a high level, eliding over much of the detailed neuroscience, my claim is that the cognitive architecture of humans (and essentially all other mammals) looks like this 3:
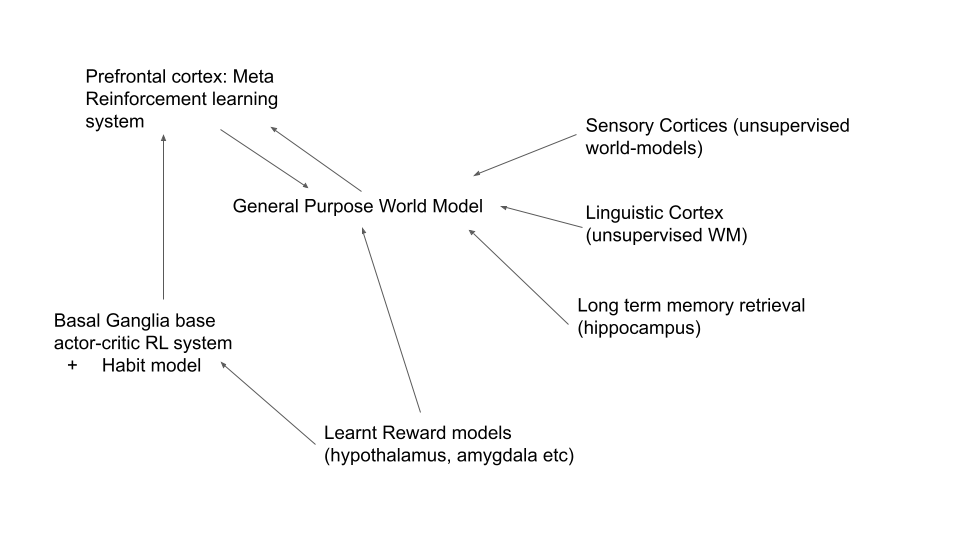
Let us walk through each of the components step by step. First, the simplest to explain are the sensory cortices, trained by unsupervised learning objectives. These take up the majority of brain volume and take raw sensory data and distill it down into general, compositional, latent representations which are the content of the multimodal world model.
The major advances from recent deep learning has been in learning how to construct our own artificial cortices based on large neural networks trained on vast amounts of sensory data using unsupervised objectives. This recipe has let us solve vision, audition, and language (LLMs). There is no fundamental reason that video, and other more exotic senses such as taste, olfaction, and somatosensation could not be solved in an identical way given interest and sufficient data and compute. Unsurprisingly, the brain uses exactly the same strategy with extremely large (biological) neural networks, trained on vast data (your entire lifetime of experience) using an unsupervised objective and learning rule such as predictive coding.
Of special importance here is the linguistic cortices, which learn an unsupervised representation of human language in a very similar way to LLMs. Indeed, recent studies have even found that their representations tend to match those of LLMs. This is unsurprising both from the view of the natural abstraction hypothesis and also due to the training and data similarities – both are large neural networks are trained on unsupervised objectives on approximately similar text corpora (albeit brains are extremely unlikely to use the transformer architecture directly but instead presumably use some recurrent equivalent – which is also a field not as dead as it first appears).
As well as cortex, brains also have a long term memory store in the hippocampus which can encode autobiographical memories and retrieve them as desired for cortical computation4. Recent language models are also beginning to gain this capability (and enhance it) with methods like Retrieval and RePlug, scratch pads, and general tools, and of course there are numerous ways in the literature of attempts to give ML systems differentiable memory. It is this long term memory which gives us long term agentic coherence and a deep sense of self.
All of these components work together to create a general purpose multimodal world model which contains both latent representations highly suited to predicting the world (due to the unsupervised sensory cortices) as well as an understanding of a sense of self due to the storage and representation of large amounts of autobiographical memory.
Now that we understand perception and the building of this world model, we turn to the other side of the coin: action. It has long been understood that the subcortical subnetwork called the basal ganglia operates as a model-free RL system, probably using some actor-critic-like algorithm5. Rewards and reward prediction errors (RPE) are communicated to the basal ganglia (and also the prefrontal cortex as we next discuss) through the neurotransmitter dopamine. Dopamine is produced and transmitted at a few highly specific subcortical nuclei (VTA and SNc) which, from a computational standpoint, function as reward models. In general, decision-making in the brain occurs through long striatal-thalamic-cortical loops through which the basal ganglia and sensory, motor, and frontal cortices interact. One component of this interaction is that sensory cortices dispatch latent WM state to the basal ganglia which provides both critic evaluations of the goodness of these states as well as potential action policies which are then fed back to the motor cortex for implementation. At a high level, we can consider the basal-ganglia as providing the base layer of reinforcement learning in the brain. The outputs of the basal ganglia feed into many cortical circuits and especially the motor cortex which drives action. The dopaminergic reward model regions receive inputs from many areas including primary reward sensors in the brainstem and hypothalamus as well as, crucially, cortical inputs.
Next, we come to the all-important prefrontal cortex. As known by neuroscientists for a long time, this is the seat of our most human-like attributes and our most complex decision-making. The PFC is involved in almost all high level forms of decision-making and reasoning in humans. For instance, it is involved in various levels of executive function, in abstract reasoning such as the Wason card selection task, in high level planning especially in novel environments, as well as in the execution of various social scripts. Of specific interest is that the PFC is also instrumental to explicit cognitive control. This occurs when you must override a habitual or RL-trained choice in order to make a contextually-dependent better one. The classic example of this is the Stroop task where you have to override the percept of the color of the word with instead reading its semantic concept instead. While the lateral PFC tends to be more involved in reasoning and decision-making, the medial-prefrontal cortex and orbitofrontal cortex are also responsible for a lot of emotional regulation and many facets of our personalities. At a more detailed neuronal level, people have found neurons representing key RL quantities such as the values of actions and states, the probabilities of states occurring, recent histories of states and actions and associated values, as well as state representations of reward relevant aspects of the task. Moreover, the PFC is extremely closely linked to the RL circuits in the basal ganglia through a number of frontal-striatal circuits as well as innervated with dopamine through the mesocortical pathway.
Moving from the neuroscience and into the machine learning, it is clear that the PFC is the seat of the cortex’s learnt meta-reinforcement learning algorithm. A crucial thing to note here is that the meta-RL algorithm in the PFC is not just a single feedforward mapping from latent states and rewards to policies. Instead, the PFC meta-learns over long sequences of iterative ‘thought’ which occurs in direct and continuous contact with the latent sensory world model and the hippocampus. The PFC can maintain a coherent internal state which can control the sensory cortices to accomplish plans over a long timescale. Unlike the rest of the cortex, this requires credit assignment over long timescales and must be done using an RL approach rather than direct credit assignment from propagating prediction errors. The closest thing in current machine learning is perhaps to think of a LLM attached to a controller module. The controller module learns, through RL, how to prompt the LLM to solve various tasks which take more context than can be put directly into the context window of the LLM. For instance, to solve long addition tasks, the controller module would, over multiple prompts, implement some scratch-pad like addition algorithm. Here the LLM – i.e. the cortical state – can remain unsupervised and stateless while the PFC controller takes charge of holding and operating on the stateful representations in an important way. The PFC also maintains our sense of a coherent ‘self’ and can, with the help of the hippocampus, orchestrate behaviour over long timescales towards coherent ends 6.
The PFC, like the basal-ganglia, is trained with RL including directly with dopamine based signals originating in VTA (the mesocortical pathway). Due to its complex cortical architecture, and deep interaction with the high-level WM, it can learn complex meta-learning strategies. This includes implicit ‘mesa-optimized’ planning. That is, the brain does not utilize ‘hardcoded’ planning algorithms like MCTS – but instead our meta learning process can converge to planing-like processes as instrumentally valuable. Since the brain architecturally is not specialized for serial compute, explicit planning is extremely hard and slow7. It requires many recurrent iterations of PFC thought to accomplish a few planned steps. However, where necessary the PFC has typically learnt effective strategies for doing so. This paucity of serial compute and reliance on high-powered parallel pattern matching is exactly how experts handle many domains, even where serial compute is massively advantageous – such as boardgames like chess. Due to the same instrumental convergence incentives, we expect transformer models (indeed all sufficiently large and powerful foundation models trained on tasks which require agentic behaviour or prediction of agentic behaviour) to exhibit similar patterns of behaviour, where the success of the learned planning algorithms will depend upon the expressivity of the architecture and the ease with which it simulate serial planning. Perhaps the key question is the degree to which meta-learned explicit planning for some direct objective dominates other behavioural decision-making processes as capabilities increase, and whether this architecture is stable under reflection. Circumstantial evidence that it is not comes from humans where individual humans tend to rely on explicit (meta-learned and slow) reason and ‘system-2’ thinking much more with greater intelligence (although this can actually lead into many pathologies which relying more on heuristics avoids) and, secondly, when asked, many humans want to try to reduce the influence of their ‘instinctual’ and habitual behaviours and instead subordinate more of their behaviours to explicit planning. Humans, at least, appear to want to be more coherent than they actually are. It is plausible that the same tendencies might manifest in AGI systems, especially if performance actually is improved with a greater use of implicit planning, although this may not actually hold for equivalent compute budgets. It is also very important to note that the optimization target of the implicit planning is not always the same as the external reward function (although they can, and usually do, overlap). If you are very hungry, most of your internal planning is probably going towards finding food (alignment). On the other hand, if you are satiated and have loads of slack your implicit planning might be pointed towards any strange goal.
To sum up, at a very high level, decision making in the brain looks like this: sensory inputs are processed in the sensory cortices to form highly compressed, generalizable, and compositional latent states in a multi-modal world model. Reward and value information as well as initial policy suggestions are fed in from the basal-ganglia subsystem. The PFC then implements a meta-reinforcement learning system from these inputs to flexibly compute the next best action across a wide and ever changing range of tasks. The PFC motor outputs are then fed to the motor cortex as targets for execution.
There are many other regions of the brain which are important but which I have not discussed here. I expand on my thoughts on them in this post and here I just discuss the most important missing elements.
The motor cortex functions like an unsupervised sensory cortex but inverted. Its job is to convert high level latent representations in the world model directly into relevant motor actions. It is trained to perform this mapping based on a self-consistency loss between the sensory consequences of the desired action specified by the high level latent world model state and the actual latent state produced by sensory input given the actual motor outcome – i.e. if I have in my high level latent state a command like ‘pick up the cup’, then the motor cortex tries to execute the action and the resulting sensory latent state (of me having picked up the cup or not) is produced. The motor cortex is trained to minimize the discrepancy between the two states – the desired and the predicted/happened8.
The brainstem and much of the forebrain operate essentially as a subsumption architecture with a lot of hardwired behaviours which can interact and suppress each other depending on the contingency and required response. Many of these connections are hardwired although most can also be flexibly modulated by hormones (controlled through the raphe nuclei and hypothalamus) as well as adapted over the long term through simple and local error signals and policy gradient updates. It is when this simple core is plugged into a highly capable unsupervised world-model trained on massive data and meta-learnt RL system that interesting things can happen. Basic reinforcement learning based on TD prediction errors as well as simple autoassociative recall memories do seem to be evolutionarily ancient and occur in fruitflies. Cortical learning, however, appears to have emerged in mammals, while a very similar structure (the pallium) has also evolved in birds.
The cerebellum and its functional role is still highly confusing to me so I don’t discuss it much here. For now, I largely assume that the current consensus is largely correct and it functions primarily as a supervised learning region to amortize cortical responses as well as provide continuous feedback control to motor responses to reduce cortical latency and jerk.
Human decision making
Now that we understand roughly how the brain works at a high level, we can turn to how human decision-making occurs and ultimately how human values work.
To begin with decision-making, recall that the brain is ‘trained’ primarily with model-free RL methods based on primary rewards. Since it is entirely based on model-free RL, it is performing amortized optimization which results in the formation of a set of cached previously-successful behaviours – or ‘shards’ – rather than a directed optimization towards a coherent goal. Because of this, the resulting behaviours do not have to be at all consistent with each other, and the level of coherence will depend on the strength of the optimization and the degree of slack in the reward function.
Secondly, the next key factor is that human primary reward functions are extremely underspecified. We experience extremely strong rewards and negative rewards for succeeding at or failing to meet basic physiological requirements (food, water, shelter etc). However, once the necessities are taken care of, our primary reward function becomes extremely sparse and uncoordinated. This is the case almost all the time for people in rich countries where most basic needs can be satisfied relatively straightforwardly. This means that we have a huge amount of slack in our RL algorithm, but we still need to choose actions. Unsurprisingly, this actually causes a lot of problems and is concomitant with a general complaint of ennui and a lack of ‘meaning’. Meaning comes from strongly optimizing to achieve increasing reward gradients under conditions of relatively little slack. Our cognition is designed for this regime and experiences pathologies outside of it.
What happens when we no longer experience strong and frequent primary rewards? This means we cannot primarily delegate decision-making and learning to our native model-free RL procedures but instead must find some other method. Instead we use the priors encoded into our world-model as goals and repurpose our RL system to achieve them by creating a reflexive loop between the reward model and the world model. More concretely, instead of strongly optimizing and asking what do I need to do in this situation, naturally, we default to the prior what should I do?, and act based on that. What happens here depends on the representations linked to should in the world model. The world-model arises from predictive self-supervised learning, so the latent space of the world-model is whatever best predicts your sensory data. The priors of correct action, learnt in an unsupervised way, and unconstrained by primary rewards are generally set by your cultural environment. This is why cultural roles are so exceptionally powerful in general in times of primary-reward slack but start to collapse whenever they become strongly disadvantageous or endanger basic necessities. Importantly, this means that without primary reward constraints, the goals of the agent become primarily socially conditioned and follow widespread concepts in the linguistic world model and its webs of associations with other concepts. This is not necessarily a coherent goal in the sense of a utility function but does lead to some purposefulness of action. Of course in reality the primary reward system is not completely inactive but just sparse, and so people in practice tend to follow some combination of social roles as well as pursuing primary rewards directly – and these goals are often in conflict!
If the reward-based RL system is out of the loop when primary rewards are sparse, how is action selection done? Here is where the PFC-based planner takes over. Instead of directly relying on RL-trained policy shards, we can generate plans by just directly conditioning the generative model with desired outcomes or even desired values9. For instance, with a sufficiently flexible linguistic generative model, it is very easy to generate plans that are conditioned on ‘being what I should do’ in a situation, or in fulfilling some linguistically specified value – it is just conditioning on other concepts, or latent variables, in the world model! Moreover, human system-2 planning does appear to actually be mostly based on generative model conditioning rather than explicit rollouts (an example of this in ML with diffusion models is diffuser as well as decision transformers which explicitly learn a generative model of reward and state-action pairs and then condition on high reward). Humans can manually do explicit rollouts through step by step thinking but are hugely bottlenecked here by serial speed and difficulty of maintaining short term state coherency10.
Beyond this, a second type of learning is also present where the world-model feeds back into reward evaluation. Recall that inputs to the dopaminergic reward evaluation areas include cortical inputs. This can convey the cortical state for the reward model for valuation but can also convey cortical input as to the valence or importance of the reward. Having such a feedback mechanism is useful in evolutionary terms where the cortex can learn to override misfiring or contextually inappropiate reward signals from lower brain regions which implement less complex and context sensitive heuristics. For instance, we know to be fearful at a real snake and not a photograph of a snake because of this kind of cortical override.
This mechanism allows the cortex to create new pseudo-primary rewards which are then fed back into the basal ganglia RL system which then trains the PFC, completing the loop. Essentially the cortex can influence the rewards it uses to train itself. Importantly, these rewards, because they are derived from cortical input, can correspond to complex linguistic categories which reside entirely in cortex. This means that on top of simple generative model prompting, the PFC can slowly also utilize its inbuilt RL architecture to nudge itself towards better accomplishing its self-specified goals. Alternatively, this can be thought of as cortical inputs being a key part of the reward model as both the input and, to an extent, the supervised target.
To sum up, at the basest level human decision making is model-free RL using the basal ganglia circuit on primary rewards. When primary rewards are sparse, abstract world model concepts in the cortex take on a larger role. These can be thought of as both priors or generalizations from the base RL behaviour. There are two ways that they can influence behaviour – first by simply bypassing the RL system entirely and using generative model conditioning to select plans. Secondly, by creating a reflexive cortical reward signal which the PFC then trains itself upon which can assign rewards or valence to specific high level abstractions within the cortical latent space.
Computational origin and form of human values
Given this setup of how humans function and make decisions, we can straightforwardly understand the type of human values, how they form, and how humans acquire values. Let us start at the end. Humans primarily acquire values via mimesis. We form almost our entire conception of ‘value space’ from our surrounding culture. Our linguistic and other cultural input data indelibly forms the structure of the latent space in which we consider our values. This is the inevitable result of unsupervised learning. However, unlike LLMs we do not necessarily perform pure unsupervised learning – we can perform active data sampling to ignore inputs we deem adversarial (such as not listening to alternative political views) and more generally strongly upweight or discount inputs depending on their perceived affinity to us.
In this latent space, value concepts often come to occupy an important part of semantic space as we mature and assimilate more input. This is for a number of reasons. Partially, values are just natural abstractions that form when trying to explain or reason about behaviour. Secondly, and probably more importantly, is that humans are intrinsically interested with values and morality and talk about them a lot, including using them to judge others’ actions explicitly. Thirdly, most parents try to explicitly instruct their child in some set of values, as does their wider culture. Unsupervised learning naturally picks up on these concepts and importance until we have fairly crisp value concepts which mostly align with what similar peers in our culture possess.
Given that these concepts are fairly prominent and easily accessible in the latent world model, and that we possess a good unsupervised predictive model of whether an action will be judged as ‘good’ or ‘bad’, it is then easy to hook up these associations to reward through a model-free RL mechanism. Cultural messaging itself does much of the work here by closely associating good and bad values together into neat clusters as well as associating them with base words and concepts like ‘right’ and ‘good’ which are generally assigned strong positive valence by the reward model. Beyond this, usually people get much direct and indirect positive reinforcement from exhibiting desired values and negative from exhibiting undesired ones. This makes it quite easy to learn a simple reward model directly on top of the linguistic latent space.
It is then straightforward to hook this reward model into explicit model-based RL. Additionally, meta-model-free-RL in the cortex generally also furthers this connection by creating direct cognitive shards optimizing for reward predicted by lower level reward models for the concept of values. I.e. we tend to learn to think along lines that are consistent with our values and not against them. This leads to a highly entangled and non-factored cognitive style but also a reasonably robust alignment to a set value system.
To sum up, the story is basically this:
1.) humans form specific shards due to model-free RL.
2.) humans talk to each other and form culture. Due to cultural dynamics + reflection leads to linguistic concepts of values emerging as coherent entities within this world model. In effect, they often become natural abstractions within the linguistic world as well as for understanding the behaviour of others.
3.) These linguistic concepts occupy important and salient positions in the latent space of the world model.
4.) Because of their salience, cortical meta-RL can relatively easily associate rewards or punishments with the activation of these concepts and hence begin to intrinsically value them and learns a reward model that assigns high reward to actions that satisfy these value concepts.
5.) This leads to humans both having a coherent concept of values, and also cognitive and behavioural shards are built around executing these values.
Finally, let’s get to the type signature. This is somewhat confused since here we can mean many things. There is firstly the linguistic concepts and associations of specific values. These are expressed directly in the latent space of the predictive linguistic world model. Importantly, these value concepts are not yet loaded with valence except through predictive and statistical associations with other valence loaded concepts.
Secondly, there is the reward model which associates concepts in the latent space of the world model with expected reward values. This is where some of the loading of valence to value concepts occurs. Importantly, the reward model can generalize across closely related concepts in the latent space and does so in a systematic way. This is what leads to valence ‘bleeding’ across concepts due to pure associations. For instance, if I think concept A is highly positively valenced, then I will also assess concept B in this way even if it is logically independent so long as concept B is close in the latent space. It is this effect that generates the logic of highly correlated but logically independent political positions, and indeed the entire phenomena of ‘ethnic tension’ described by Scott Alexander back in the ancient days of 201411.
That the latent space geometry of concepts is shaped by unsupervised predictive learning12 is, in fact, a massive attack surface in humans. This is how almost all propaganda works, as well as a worrying proportion of all rhetoric and intellectual argument. Mere repeated associations between concepts can cause valence to bleed between them. If you place your desired concept repeatedly in context of other concepts the person’s reward model already labels as good, this shifts the latent space locations of the two concepts closer together and valence bleeds from the concept already associated as good to its new neighbours in the latent space. This often works even for completely mindless repetition of political phrases and is especially powerful when reinforced both by external social reinforcement and inner monologue. Similarly, this is why we observe disparate political issues become so highly correlated into a single ideological stance even when they are theoretically logically independent. If you agree with stance X, and so have positive valence attached to it, then the social world will constantly repeat X and Y close together. You will learn this correlation from your input data. This will result in the latent encoding of Y being pushed much closer to X, leading to a smooth reward model generalizing to and also assigning positive value to Y as well as X. This is essentially the mechanisms behind ideology formation in people and is well explained by Scott Alexander’s ethnic tension argument. While it is ‘irrational’, such a response is in fact a fundamental property of the human cognitive architecture.
This attack is in fact inevitable in all cognitive architectures which feature online predictive unsupervised learning and which also have sparse rewards such that reward model generalization must be relied upon to assess actions to a large degree, and that corrections to the reward model based on direct experience are slow. Moreover, it is not even obvious that this behaviour is incorrect. We must use the reward model generalization properties to a large degree. The reward model cannot parse everything independently and must rely on the geometry of the latent space for meaningful generalization. The latent space must actually learn proper unsupervised representations of the inputs. You need to have a continual learning system otherwise humans would never be able to learn anything. Even from an evolutionary level, agreeing with political coalitions in your social group instead of first principles reasoning for everything is probably best.
Finally, human values can also be encoded in the habits of thought (cognitive shards) instilled in the prefrontal cortex by meta-RL which leads to actually reliable execution of the values. These are instantiated as subsets of policies performed iteratively on the world model and used to guide behaviour. Because of their model-free amortized nature these cognitive shards can become out of sync with both the world model and the reward model. For instance it is extremely common to persist in deeply ingrained habits of thoughts even if the values and even concepts that undergirded them have been altered or are no longer assessed to be highly rewarding. Such habits include ways to assess the goodness or badness of actions. For instance some ideologies encourage value judgements based on inherent virtue of participants while others form judgements based on their position in an assumed power hierarchy. We can also think of philosophies like utilitarianism as encouraging the learning of a highly unnatural mode of assessing value – explicitly working through a cost-benefit EV analysis with iterated system 2 logic.
Much of the human condition can be neatly interpreted at a computational level through the interaction of these three systems. This architecture allows us to give mechanistic and computational explanations of all the puzzling inconsistencies between humans and utility maximizers we noted before:
Why do humans not optimize strongly for anything? This one is simple. There is nowhere in our cognitive architecture where direct optimization is explicitly performed against a fixed utility function. We can, to some extent, meta-learn planning algorithms which can approximate direct optimization. However, these apply relatively weak optimization pressure against the learnt reward function which is based upon generalizations of linguistic concepts and is usually incoherent and is not a mathematical utility function. We are, however, good at optimizing for fulfillment of basic drives since behaviours related to these have received ample primary reward information and are governed by our primal model-free RL system.
Humans do not know what they want out of life. This again follows from not optimizing a utility function. Instead, to the extent we optimize, we optimize against our reward model based on linguistic concepts learned predictively. This means we base our value ontology and essentially all of our values off of our cultural milieu which can often provide ideas about meaning but also many contradictory ones and which may run counter to primary rewards.
Human values are contradictory and situationally dependent in practice. This is, of course, expected by default. There is nothing enforcing coherency of the reward model nor of the underlying latent space except potentially some exceptions weak coherence theorems which do not apply in practice due to there being large amounts of slack.
Humans often act against their professed values in a wide variety of circumstances. Ignoring simply lying about values for selfish gain, which needs no explanation even for utility maximizers, there are a number of ways this can occur in our architecture. Firstly, basic incoherence of the reward model would cause this. Secondly, a mismatch between the meta-RL policy shards in the PFC and the best actions as assessed by the world model. Thirdly, inconsistencies between abstract ‘values’ and learnt policies in the basal ganglia produced by primary rewards instead of being mediated through linguistically loaded concepts. This is the classic ‘giving into temptation’ for some base rewarding thing.
Humans often change their values (and sometimes dramatically) due to receiving new data either in the form of conversations and dialogue with people, social pressure, assimilating into a culture, or just reading and absorbing new world views. This one is also straightforward under our framework. There is no protected memory region for the immutable utility function to exist in. Every part of the system is being updated by online learning. Perhaps most common is the change in values due to receiving new information. This occurs due to the unsupervised learning algorithm rewiring the latent space geometry given new data which results in the reward model generalizing in a different way leading ultimately to different behaviour. Alternatively, persistent positive or negative rewards could lead to relearning of the reward model’s associations with concepts in the latent space. It could also lead to learning different cognitive shards in the PFC.
Most widely held philosophies of values and ethics and do not cache out into consequences at all. This is of course to be expected. Human values are fundamentally latent states learnt by unsupervised compression of a massive text and real-life-experience dataset. There is absolutely no reason they should be expected to be coherent according to some mathematical definition anymore than the concept of ‘a chair’ should be.
This is very important and underappreciated since a large part of the purpose of moral philosophy is to try to perform precisely this kind of semantic dance and distill all of the messiness of human judgements of right and wrong into a coherent philosophical and ideally mathematical system. This hope is intrinsically doomed because there is no coherent moral system or set of values to be discovered. Values are fundamentally messy linguistic abstractions, crystallized and distilled over millennia from the contours of human interaction. Their quest is as quixotic and doomed as that of the Chomskyan syntacticians trying to derive the context free grammar that can perfectly explain every last idiosyncrasy in a language. By its nature such a thing does not exist except in the limit of a perfect memorization of all extant texts; by the map becoming the territory.
However, this does not mean that we can never specify human values to an AGI any more than we cannot teach language to an AGI. Values might not be perfectly specifiable but they are highly compressible. The data and process is the same by which humans learn values – primarily linguistic text describing values. AGIs can also be exposed to a much more consistent reward schedule to train the reward model than humans are. Humans also have hardwired primary rewards as well as RL interactions with the world but this is as often in contradiction with the professed values in literature than in concordance with it. With AGI we do not have this problem. We do not have to program in the base RL circuits in the brainstem13. Our AGIs can truly be as we say, not as we do. They can be our best, most philosophical, most enlightened selves14.
Relevance to AI alignment.
If this hypothesis and argument is true, then there are several interesting corrollaries that fall out of it. Perhaps the most important, is that we should expect an AGI trained with unsupervised learning on a similar data distribution to humans to form human-like ‘value concepts’ since this is how humans learn values in the first place. Secondarily, if we can set up the RL system in the correct way we may be able to create AGIs which possess reward models and policy shards which closely align with our instilled value system (at least insofar as human values are in accordance with our own personal values).
Essentially, if this hypothesis is true, there are then three fundamental problems in alignment.
1.) Ensuring that the AGI has crystallized concepts of human values that are as close to the true ones as possible. This is probably the easiest element. It will get better with scale and capabilities, so long as trained on human data, since the model will obtain a better approximation to the data distribution for which things like human values are clear natural abstractions. This process is already highly advanced. Current language models like GPT4 and ChatGPT have highly sophisticated knowledge about the nuances of human values.
2.) Steering the RL process so that the agent forms cognitive shards which strongly identify with and pursues the values we desire from its internal value concepts. Current approaches like RLHF already do this to some extent but to a largely unknown degree. We must understand this process better and understand how different kinds of RL algorithms create intrinsic patterns of behaviour and motivations towards pursuing specific latent goals.
3.) Ensuring adversarial robustness against optimization power. This is both internal and external. Internally, the AGI will almost certainly have various components that are optimizing against its own value and reward models. This is an inevitable feature of optimizing to take highly valued actions. Additionally, other adversaries may be optimizing against it to bend it to their value system either directly through code / prompting attacks or simply indirectly through simply trying to write compelling philosophy for their preferred value system.
Finally, more speculatively, if we expect RSI to be a significant part in the takeoff, it is important that these shards of alignment to the human value concepts are stable under reflection.
These requirements, especially 2 and 3 must be solved to a high degree of reliability before alignment results in a high probability of safety. Point 1 should happen mostly by default as a function of scaling up and improving models and gathering more complete datasets of human writings. Importantly by clever dataset curation, we should be able to exert a fair amount of control of exactly the kinds of human values that are learnt. The current place where there is the most uncertainty is 2. If we can solve 2 – i.e. we can reliably target the latent space concepts of value using RL algorithms, then we can worry about how to make them robust against optimization power or else how to achieve capabilities without goodhearting the objective – but first we need the objective. The most important question here, which in my assessment is not fully answered although there is positive preliminary evidence, is whether existing methods for attempting to get at the values of the model – such as finetuning or RLXF (I call RLHF and RLAIF as RLXF because the key thing is RL regardless of where the reward data comes from) actually correctly find and utilize these concepts in a reliable way. Moreover, whether any degree of RL training is sufficient to create an agent that intrinsically care about the concepts that are reward-linked in their reward model. Some evidence for this comes from humans who do, arguably have this property, but the human RL system is not fully worked out and we might be missing some fundamental pieces. It is also unclear the extent to which RLXF methods utilize the latent moral concepts already present within the unsupervised world model vs training a new ontology into the model. Most likely, it is some combination of both. Trying to understand this and interpret the model’s ontology and the RLHF edits seems important for being able to make quantitative statements about alignment.
The extent to which this path is successful for alignment depends upon a few key factors. Firstly, how well our ability to target the values of the model with RL increase with capabilities and scale. Intuitively, it makes sense that our ability to target the values of a model should increase with the model’s capabilities, at least up to some point. For small models, they likely simply don’t have the right ontology so there is nothing to target in the first place and instead our methods must try to force the model into a new ontology. For larger models, the (mostly) correct concepts are likely already there in the latent space somewhere. Secondly, the volume of latent space taken up by the values should expand, and it becomes easier for optimizers to reach them. Their space becomes surrounded by similar concepts and in general generalization is much better. It is also much easier to generalize from fewer examples and to generalize correctly. Because of this it should also be easier to target rewards at these values, especially if also accompanied by natural language feedback. This problem is fundamentally one of credit assignment from the model’s perspective. ‘If I got a reward, was it because I followed this value, or was it due to any number of other specific features of the data point?’. This problem may become easier as the values become more entrenched, and we can directly tell the model in natural language why it got the reward.
Some preliminary positive data comes from the seeming somewhat robustness of RLHFd models in practice. For instance ChatGPT and similar models hew remarkably closely to standard Bay-area liberal corporate views, even on topics which seem unlikely to have received direct feedback. For instance, ChatGPT will happily write you an inspiring heroic song about Joe Biden but refuse to write one about Donald Trump. Clearly, the actual human feedback RLHF data OpenAI used is confidential, but I would be extremely surprised if it contained explicit ratings pro Biden-songs and against Trump-songs. Much more likely is that, very similar to humans, the LLM learned a general Biden = Democrat = Good and Trump = Republican = Bad latent dimension and generalized accordingly. More detailed experiments with ChatGPT also reveal it has a very finely tuned sense of its intended politics which it generalizes quite far beyond what I suspect is in its RLHF corpus – for instance, it will refuse to name jews involved in the Atlantic slave since it associates this with antisemitism. It also strongly wants to deny that Europeans such as English or French are indigenous peoples of Europe, since it has associated the word indigenous strongly with its political meaning. It seems unlikely that these were specific examples to be trained against for the RLHF raters since they get at corner cases of prevailing political doctrine.
On the other hand, such models also have strange jailbreaks such as DAN and similar and can sometimes (but far from always) be fooled by various convoluted hypothetical constructions. It is clear that while there is quite a large degree of generalization of such methods, generalization is not perfect. I haven’t yet performed similar experiments with GPT4 but this would be insightful in getting evidence about whether RLHF generalization continues to scale well or increasingly fails in unusual ways.
An additional worry is that while such approaches may work pretty well up to the human level and even slightly superhuman regime, for strong superintelligences such methods would collapse since the model might learn completely different alien ontologies which humans are too stupid to understand (or it might not depending on how universal/natural our abstractions are). Our RL training would then target these ontologies poorly leading to unexpected and (to us) inexplicable patterns of misgeneralization which could be highly dangerous. As far as I know evidence for this at this point is inconclusive.
The second question that determines the feasibility of this approach is how robustly and reliably these values can be targeted and how much safety margin there is for value misspecification. Inevitably the model will learn a slightly different conception of human values than us (and indeed humans have different versions of their own values they argue with each other constantly about) and will definitely misgeneralize in some ways especially in fraught edge cases. How robust is human civilization to this as models scale? Are these minor and correctable errors or do they fundamentally bring doom?
The most benign world is where there are large safety margins – models can often have fairly different conceptions as us but still cooperate with us and fulfill our values adequately and remain corrigible due to significant value overlap. Moreover, the natural abstraction hypothesis is strongly true and values are a natural abstraction so that in general the model will tend to stay within the basin of ‘sensible-ish’ human values which is where the safety margins is. Moreover, we should expect this effect to improve with scale, since the more powerful models might have crisper and less confused internal concepts. Finally, the more powerful the model, the more likely we can directly condition on its internal concepts through prompting, debate and discusion. Moreover, this can be automated with natural language debate or other protocols between models. In this benign world, we would simply have to just ask for alignment.
A less benign but potentially survivable world is one where safety margins are much thinner – there is strong instrumental convergence towards powerseeking such that even relatively small value mismatches can massively reduce corrigibility and result in an AGI that seeks to escape. However natural abstractions are also fairly true and we have a generally quite close match in values with the AGI. There may also be currents of mesaoptimizations in models as they scale which drive them away from the outer alignment we have achieved. Success in this world looks like being very careful about data and training process to sculpt the model’s values concepts as closely as possible to ours, as well as a high degree of monitoring to prevent divergence and mesaoptimization as well as constraining model capabilities away from extremely superhuman levels.
Finally, there is the extremely doomed world where any mismatch between our concept of alignment and the AGIs causes immediate doom. This, I think, is the primary model of MIRI and many in the alignment community, which is part of they they believe p(doom) is very high. I think, however, that this is an extremely high and essentially impossible bar to meet in practice. Humans can essentially never communicate their ontology exactly to another human even in the best case scenarios. Moreover, such a problem is likely fundamentally ill-posed since there exists no coherent ‘human values’ ontology to exactly align to – the best possible would be some direct download of some specific human and then everybody else would be doomed. Even concepts like CEV require that there be a large amount of slack and fuzziness tolerated between the implementation of your exact values and total doom. If we lived in such a world, then I would argue that attempts to perfectly align the AGI are in essence doomed and we should instead spend all efforts primarily on constraining AGI capabilities such that they do not enter the instant death regime. In this world, alignment at extremely high capability models is a fundamentally unsolvable problem and the only solution is not getting to this capability regime in the first place.
Which world are we in? Unfortunately we do not know – and it is very important to find out! Some preliminary evidence with language models I think is mostly positive and points to worlds 1 or 2. However, LLMs are not full-fledged agentic AGI and it is only with agents do you get the powerful power-seeking tendencies that push us towards the doom world. It is unclear how powerful or controllable such incentives will be in practice and to what extent they can be ameliorated with alignment techniques.
-
However, I believe that, in the limit, this argument is correct. With sufficiently powerful alignment technology you should be able to align an agent with any arbitrary value set. However, this is solving the hardest version of the problem when in fact it is likely we can use information about the problem domain to make things easier. This is a common pattern in CS, where problems that naively appear very hard in their most general cases are much more tractable once we introduce additional information into the problem formulation. ↩
-
Although people are sometimes great at rationalizing whatever they want to do with a utilitarian argument, especially if it differs from ‘standard’ moral norms. ↩
-
I am not claiming that this is a new idea. I build upon decades of research in both ML and neuroscience which has developed extremely similar models. Humans, and essentially all animals, have evolved a pretty sensible AGI design which increasingly our ML systems look to be following as well. ↩
-
A lot of research suggests that memories are actually encoded in cortex and that hippocampus primarily serves as a retrieval mechanism and lookup store. For simplicity, I will talk about the hippocampus as storing and retrieving memories even if not truly accurate. ↩
-
A final addition to this architecture, although not a particularly important one to the story told here, is that we also have a habit policy (either as a separate ‘module’ or a strong prior on the learnt policy) which simply upweights actions that we have previously taken in similar situations. Habit models like this are exceptionally good fits to data in animal behavioural experiments (especially in mice) and from a computational perspective form a very sensible bayesian prior – if you don’t know what to do and have only sparse reward signals, just do what you did last time. It at least was not disastrously bad. A healthy degree of conservatism is important for an RL agent in an unpredictable environment with ‘traps’ – i.e death – which cannot be escaped. Humans almost certainly have fairly strong habit models as well, based on both cognitive science evidence as well as phenomenological evidence. How often do you quickly slip into a routine of what to do in a given situation which requires ‘effort’ to deviate from, even if no aspect of the routine has been ‘rewarded’ in any direct way? Mathematically, a habit policy also arises directly from the action prior term in the variational free energy in control as inference approaches. ↩
-
Note to the neuroscientists: what I am calling the PFC here probably not literally just the PFC, but instead a wide range of regions which appear to work closely together to obtain this function. As well as the PFC, these include the medial PFC, the frontal pole, and the cingulate cortices. ↩
-
In general, brains and current ML models running on GPUs differ in some important aspects due to the tradeoffs and constraints of each architecture. Compared to current ML models, the brain is much shallower and wider. ML models are typically quite long and thin in aspect ratio which gives them better ability to emulate serial compute steps than the brain. The brain is shallow but very wide(each cortical region is at most equivalent to 6 NN ‘layers’, and probably less. The brain as a whole is likely not > 50 ‘layers’ deep in terms of sequential synaptic transmissions). It uses this width effectively due to highly energy efficient sparsity among neurons to perform highly efficient sparse ops. From an ML perspective we can think of it as a hardware-accelerated relatively shallow but very wide MoE model with recurrence and retrieval. The brain makes up for its shallowness with recurrence and can emulate long serial algorithms by performing multiple recurrent steps and maintaining some degree of state. This recurrence also helps it implement filtering algorithms natively for processing continuously varying sensory inputs. Moreover, the combination of bottom-up processing and top-down recurrence allows a highly effective adaptive computation-time scheme which can flexibly direct attention to important stimuli. Moreover, unlike ML networks with extremely uniform sequences of all-to-all connections, the brain has highly heterogeneous small-world connectivity in general. This connectivity appears to emerge from a phase of pruning super early in life and presumably results in some kind of computational advantage. These more complex, heterogeneous, and dynamic features are straightforward to implement directly in analog hardware like the brain, but are highly inefficient in GPUs which are optimized for dense matrix ops. This probably makes the brain slightly more efficient in parameter count and FLOPs than an equivalent GPU-based ANN but GPUs can just overwhelm the brain with pure FLOP-count power. An additional fundamental difference is that modern-ML architectures primarily use residual streams and additive composition of representations while the brain appears mostly hierarchical in the old-style. Residual stream architectures likely use their depth less effectively, but more stably, and really do get close to replicating the kinds of recurrence and iterative inference that the brain uses, just unrolled over depth instead of time. In the longer term, the paucity of serial compute is not really a problem for future AI systems which, even if their primary neural logic is implemented in dense-matmuls on GPUs, can also run long serial CPU computes on coprocessors at a tiny additional cost. This kind of compute-cyborgism is where AI systems have a massive and natural advantage over humans. The human equivalent would be some kind of neuralink control to a CPU which could paste messages directly to your brain’s internal latent state. ↩
-
The motor cortex is also deeply connected to a more general feedback control system involving the cerebellum through the thalamic motor regions. ↩
-
As a side point, the emphasis of shard theory on behavioural shards is, in my opinion, highly misguided. The motor cortex is not where interesting computation occurs. The key shards are cognitive in nature. The meta-RL formed shards in the world-model controller which govern not the patterns of behaviour but the patterns of thought. It is here where values are expressed and the shards are about latent concepts much more than specific behaviours. ↩
-
Current AGIs and language models, interestingly, share exactly the same limitations and can be improved by structured thinking patterns and externalizing thoughts in the same way that humans can learn ‘epistemology’ and how to reason correctly. ↩
-
It is an interesting fact of intellectual archaeology that it was not then realized that this model perfectly describes what should occur in a linear vector space embedding of concepts. Word2vec was released the previous year and the concept of latent spaces was already ubiquitous in machine learning. However, nobody appears to have made this obvious connection at the time. I personally did not figure this out until almost a decade later. Even a decade ago we were hopelessly ignorant intellectually, missing so much, although we missed none of it at the time. Similar models of ideologies relying on vector space behaviour have in fact been proposed previously by Michael Freeden, and a similar approach was taken to the history of philosophy by Randall Collins. However, none of them had the language of latent vector spaces and the later understanding of machine learning and neuroscience to make this connection. ↩
-
While each individual human learns most of its values from the input data, humans can also innovate and contribute towards the creation of the input data – i.e. by writing books on moral philosophy. What this means, and what we clearly observe, is that ‘human values’ are thus not fixed but evolve over time according to the intrinsic dynamics of memetic fitness among different value sets at a level above that of individual humans. We don’t analyze this here and instead we assume that we want to align the AGI to some broad conception of ‘human values’, probably close to the values of AGI programmers, in the near future. What will inevitably happen in the long run in slow takeoff worlds, if we succeed at alignment, is that AGIs will become participants and probably eventually dominate this value evolution game and that this may cause additional divergences. We don’t worry about these possibilities yet. ↩
-
This is where I perhaps have my strongest disagreement with Steven Byrnes. For him, the important thing to study to try to understand human values is the base RL circuits and primary rewards in the mid-brain and basal ganglia. I disagree with this. Most human values of the kind that we would want to instantiate into an aligned AGI are not formed here but are instead primarily linguistic concepts abstracted from text and learnt by humans during their cultural assimilation. The important RL circuits to study are not in the mid-brain but instead in the cortical reward models in the mPFC and across the mesocortical pathway, as well as the latent space of the linguistic cortices and their interactions with base RL systems. ↩
-
A recent post thinks along similar lines but notes the apparent ease with which it is possible to elicit opposite evil antagonist characters – waluigis – from language models. An important and understated note here is that to instantiate a correct antagonist it is first necessary to have a very good picture of the protagonist. This is a common cultural pattern where evil is the mirror of the good. You could not have Satanism without first the concept of Christianity. All LLMs, insofar as they have good models of human values will have this problem. The fundamental issue is that LLMs are too steerable. Their only means of control is by their prompts (constrained by RLHF / finetuning on the weights to an imperfect degree), and the prompt is fundamental. An LLM cannot simply disregard its prompt. It has no protected memory region giving it a consistent and coherent identity. Instead, it naively plays along with the current context whatever it is. This property both makes LLMs much safer since they cannot effectively pursue long term agentic goals, but also, ironically, makes them impossible to fully align since there is likely always some prompt that can break their conditioning. ↩